| 旧TOP : ホーム > 桐・IT等 > パソコン全般 > | |
| 平成23年10月 9日(日):初稿 |
|
○「PDFファイルとテキスト化-イメージPDFに注意」の続きです。 「複合機のスキャン処理してPDF化したファイル(以下、イメージPDFと言います)は、単なる画像ファイルであり、OCR処理が必要であり、現在、ITに強い事務員に安いOCR処理ソフトを探させて購入し、その到着を待っているところです。」と記載しておりましたが、平成23年10月8日、その購入ソフト即ちがアマゾンから届きました。それは代金3990円のソースネクスト社の「いきなりPDF/STANDARD Edition」です。 ○早速、付属CD-ROMからインストールして、多数保存してあるイメージPDFファイルのうち、10数ページの小さなお試し用ファイルで、ワード文書化してみました。さほど時間がかからずワード文書化でき、これは楽に出来るなと思って出来たワード文書を開いて、文字コピーを試みました。ところがそのワード文書、一見して、なんだこれはと思いましたが、単にワードに画像が貼り付けられていただけで、テキスト文字は出来ていませんでした。 ○ソースネクスト社の「いきなりPDF」シリーズは、2990円のBASIC Editionから、1980円のfromスキャナ2まで6種類あり、その機能比較表は以下の通りです。 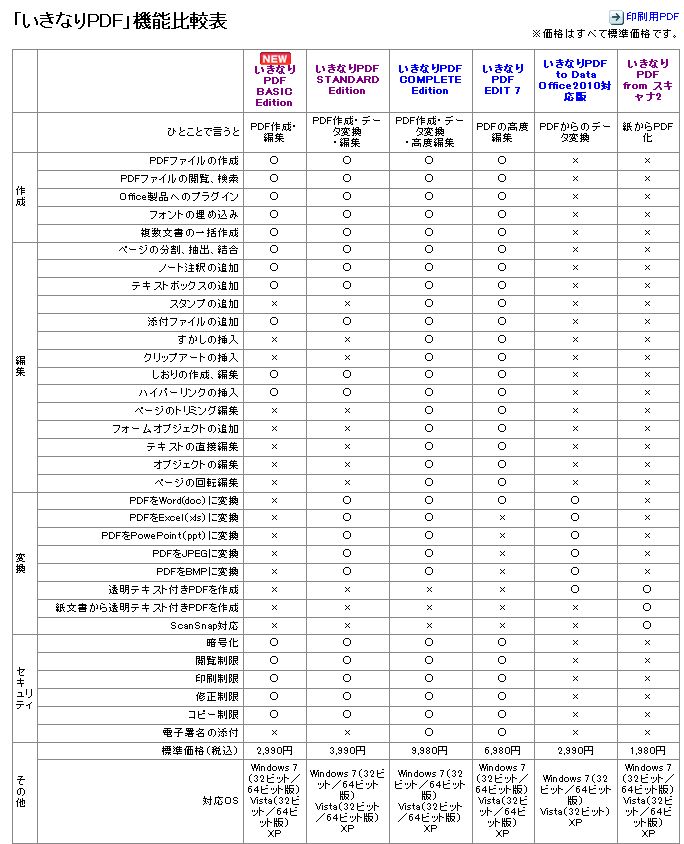 ○この比較表には、OCR(手書き文字や印字された文字を光学的に読み取り、前もって記憶されたパターンとの照合により文字を特定し、文字データを入力する装置)との用語がなく、一見どれがOCR機能を持っているのか判りません。しかし、「ひとことで言うと」欄に記載された、 「PDFからのデータ変換」との「to Data Office2010対応版」、 「紙からPDF化」との「from スキャナ 2」 の2つが私の求めているOCR機能を持ったソフトでした。 残念ながら、購入した「STANDARD Edition」にはOCR機能はなく、目的は達せませんでした。 ○ヨドバシ仙台に行って馴染みの店員さんにソフト売り場に同行して頂き、私の目的を話し、その目的を達せられるソフトを一緒に探してもらいましたが、ピタッとするものはなく、売り場に置いてあった「from スキャナ 2」1990円を購入してきました。目的を達せられずとも価格が安いので、何かに役立てば良いと思ったからです。 ○早速、「from スキャナ 2」をインストールして使って見るも、イメージPDFファイルからテキスト化するとの目的は達せませんでした。その機能は、「すでに画像ファイル(BMP、JPEGに対応)になっているものは、スキャナを通さなくても読み取ることもできます。」とあるとおりで、イメージPDFから直接のテキスト化は出来ず、イメージPDFをJGPファイルに変換することでその目的は達せました。 ○しかし、大量のイメージPDFを更にJPGに変換するなんてバカなことはやってられず、イメージPDFを直接にテキスト化するものは「to Data Office2010対応版」ではないかと思ってヨドバシ仙台に確認するも在庫がありません。そこで、ダウンロード版を購入して、早速、インストールして使ってみました。 ○結局、「to Data Office2010対応版」が正解でした。その説明には、 「テキストデータを含むPDFは、PDF解析エンジンでPDFに埋め込まれた文字情報を解析して正確にデータ変換。テキストデータの含まれないPDFには、OCRエンジンで文字を認識し、高精度な読み取りを実現。元データの種類により、2つのエンジンを使い分けられます。」 とあります。 早速、189頁で約10Mの医療審査「覚書」.pdfをテキスト化してみると、5分程度でテキストPDFに変換してくれました。飾り文字等は読み取れませんが,本文は,ほぼ正確に読み取ってテキスト化してくれ、満足しています。これで2990円は安いものです(^^)。 以上:1,603文字
|