| 旧TOP : ホーム > 桐・IT等 > 桐の基礎講座 > | |
| 平成20年 9月13日(土):初稿 |
|
○「平成20年新司法試験合格者発表」で法務省の「平成20年新司法試験法科大学院別合格者数等pdfファイル」のテキストデータ部分を取り込みテキストファイルとしたものを桐に読み込んで桐ファイル化したものを紹介しました。 ○「他のファイルデータの読み込み」で桐ファイルへの他ファイルデータの読み込み方法の基本を説明していますが、法務省の「平成20年新司法試験法科大学院別合格者数等pdfファイル」のテキストデータ部分を取り込みテキストファイルの一部は以下の通りです。 愛知学院大法科大学院22 21 16 3 0 愛知大法科大学院55 42 35 29 16 青山学院大法科大学院88 87 61 41 15 大阪学院大法科大学院54 53 28 14 1 大阪市立大法科大学院102 102 82 62 33 (以下省略) ○数字部分「22 21 16 3 0」は半角スペースがあるのですが、どういう訳か大学名と最初の出願者数「22」の間のみ半角スペースがありません。そのため桐で読み込むときは以下の通り項目「出願者数」は外しました。読み込み条件は以下の通りで、項目間の区切り文字を「その他」として「半角スペース」を指定します。 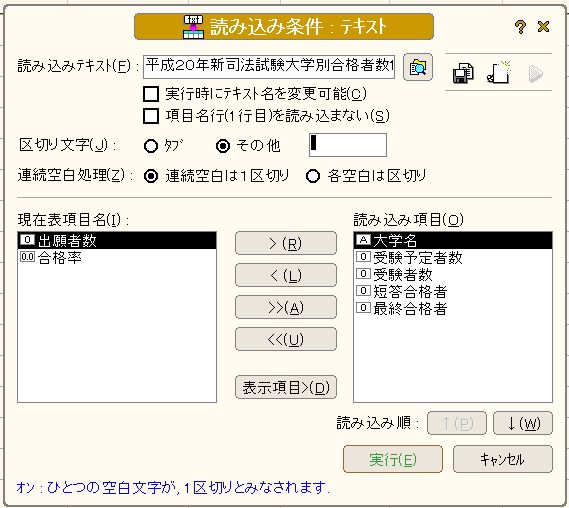 ○これで読み込みを実行すると以下のように項目「大学名」のデータに出願者数データが続いて読み込まれます。大学名と出願者数データの間に半角スペースがないため区切りにならないからです。 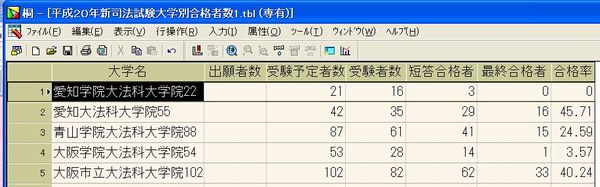 このため「愛知学院大法科大学院22」の内「22」のみ切り離して項目「出願者数」に入力しなければなりませんが、その方法として桐には項目置換という便利な機能を用意しています。これは読んで字の如く特定の項目のデータを置き換える機能で、これを実行すると次のようなウインドウが出てきます。 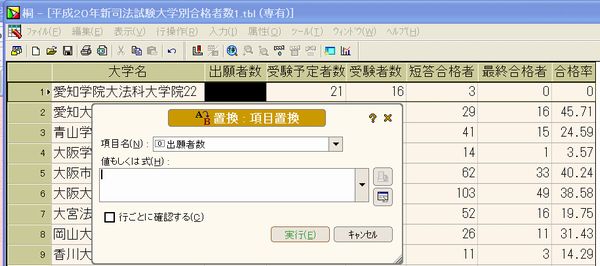 この項目置換に「愛知学院大法科大学院22」の内「22」のみ取り出して入力する方法は、関数 #部分列( str , n ) を利用しますが、その説明は以下の通りです。 str の n 文字目から最後の文字列までを取り出す。 n に負の値を指定すると、n バイト目以降の文字列を取り出す。 指定するバイトが全角文字の後半に位置する場合は、1 バイト手前から取り出す。 【例】 #部分列("ABCDEFG",4) → "DEFG" #部分列("漢字文字列",-5) → "文字列" #部分列("漢字文字列",-2) → "漢字文字列" 《別名》 #SSTR #部分列 問題は、「愛知学院大法科大学院22」の最初の「2」の取り出し方法ですが、大学名の長さが各レコードによって異なりますので,特定の数字を入れることは出来ません。この方法として便利なものが関数 #文字位置( str1 , str2 ) で、その説明は以下の通りです。 str1 の中に str2 が含まれていれば、その文字位置を返す。 含まれていなければ 0 を返す。 文字位置は先頭文字を 1 とする。 【例】 #文字位置("ABCDEFGHIJKL","DEF") → 4 #文字位置("ABCDEFGHIJKL","XYZ") → 0 ここでは、大学名データには全て「大学院」がありますので、これに着目して以下のような計算式を入れます。 #部分列([大学名], #文字位置([大学名],"大学院")+3 ) これは項目「大学名」のデータの中の"大学院"と言うデータのある文字位置に3を加えた文字位置即ち"大学院"の次のデータから以下の文字列を取り出すと言う関数式で、 "愛知学院大学法科大学院22"の場合は、 "大学院"の文字位置は9番目なので、これに3を加えた12番目以降のデータ即ち"22"だけ取り出します。 ここで重要なことは、項目「大学名」と項目「出願者数」を同じデータ型即ち文字列にしておくことで、これを実行すると次のように項目「出願者数」にデータが入力され、この後に項目「出願者数」のデータ型を整数に訂正します。 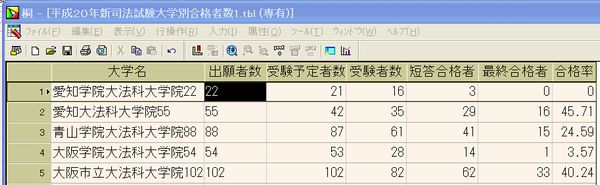 次に項目「大学名」の"愛知学院大学法科大学院22"から"22"を削除する必要がありますが、これも項目置換で次の計算式により簡単に削除できます。この意味は別コンテンツで説明します。 #文字置換([大学名],#部分列([大学名],#文字位置([大学名],"大学院")+3),"") 以上:1,784文字
|